File Format¶
Dataset Directory¶
A Lance Dataset is organized in a directory.
/path/to/dataset:
data/*.lance -- Data directory
latest.manifest -- The manifest file for the latest version.
_versions/*.manifest -- Manifest file for each dataset version.
_indices/{UUID-*}/index.idx -- Secondary index, each index per directory.
_deletions/*.{arrow,bin} -- Deletion files, which contain ids of rows
that have been deleted.
A Manifest file includes the metadata to describe a version of the dataset.
1// Manifest is a global section shared between all the files.
2message Manifest {
3 // All fields of the dataset, including the nested fields.
4 repeated Field fields = 1;
5
6 // Fragments of the dataset.
7 repeated DataFragment fragments = 2;
8
9 // Snapshot version number.
10 uint64 version = 3;
11
12 // The file position of the version auxiliary data.
13 // * It is not inheritable between versions.
14 // * It is not loaded by default during query.
15 uint64 version_aux_data = 4;
16
17 // Schema metadata.
18 map<string, bytes> metadata = 5;
19
20 // If presented, the file position of the index metadata.
21 optional uint64 index_section = 6;
22
23 // Version creation Timestamp, UTC timezone
24 google.protobuf.Timestamp timestamp = 7;
25
26 // Optional version tag
27 string tag = 8;
28
29 // Feature flags for readers.
30 //
31 // A bitmap of flags that indicate which features are required to be able to
32 // read the table. If a reader does not recognize a flag that is set, it
33 // should not attempt to read the dataset.
34 //
35 // Known flags:
36 // * 1: deletion files are present
37 uint64 reader_feature_flags = 9;
38
39 // Feature flags for writers.
40 //
41 // A bitmap of flags that indicate which features are required to be able to
42 // write to the dataset. if a writer does not recognize a flag that is set, it
43 // should not attempt to write to the dataset.
44 //
45 // The flags are the same as for reader_feature_flags, although they will not
46 // always apply to both.
47 uint64 writer_feature_flags = 10;
48
49 // The highest fragment ID that has been used so far.
50 //
51 // This ID is not guaranteed to be present in the current version, but it may
52 // have been used in previous versions.
53 //
54 // For a single file, will be zero.
55 uint32 max_fragment_id = 11;
56
57 // Path to the transaction file, relative to `{root}/_transactions`
58 //
59 // This contains a serialized Transaction message representing the transaction
60 // that created this version.
61 //
62 // May be empty if no transaction file was written.
63 //
64 // The path format is "{read_version}-{uuid}.txn" where {read_version} is the
65 // version of the table the transaction read from, and {uuid} is a
66 // hyphen-separated UUID.
67 string transaction_file = 12;
68} // Manifest
Fragments¶
DataFragment represents a chunk of data in the dataset. Itself includes one or more DataFile,
where each DataFile can contain several columns in the chunk of data. It also may include a
DeletionFile, which is explained in a later section.
1// Data fragment. A fragment is a set of files which represent the
2// different columns of the same rows.
3// If column exists in the schema, but the related file does not exist,
4// treat this column as nulls.
5message DataFragment {
6 // Unique ID of each DataFragment
7 uint64 id = 1;
8
9 repeated DataFile files = 2;
10
11 // File that indicates which rows, if any, should be considered deleted.
12 DeletionFile deletion_file = 3;
13}
14
15// Lance Data File
16message DataFile {
17 // Relative path to the root.
18 string path = 1;
19 // The ids of the fields/columns in this file.
20 //
21 // IDs are assigned based on position in the file, offset by the max existing
22 // field id in the table (if any already). So when a fragment is first created
23 // with one file of N columns, the field ids will be 1, 2, ..., N. If a second,
24 // fragment is created with M columns, the field ids will be N+1, N+2, ..., N+M.
25 repeated int32 fields = 2;
26} // DataFile
The overall structure of a fragment is shown below. One or more data files store the columns of a fragment. New columns can be added to a fragment by adding new data files. The deletion file (if present), stores the rows that have been deleted from the fragment.
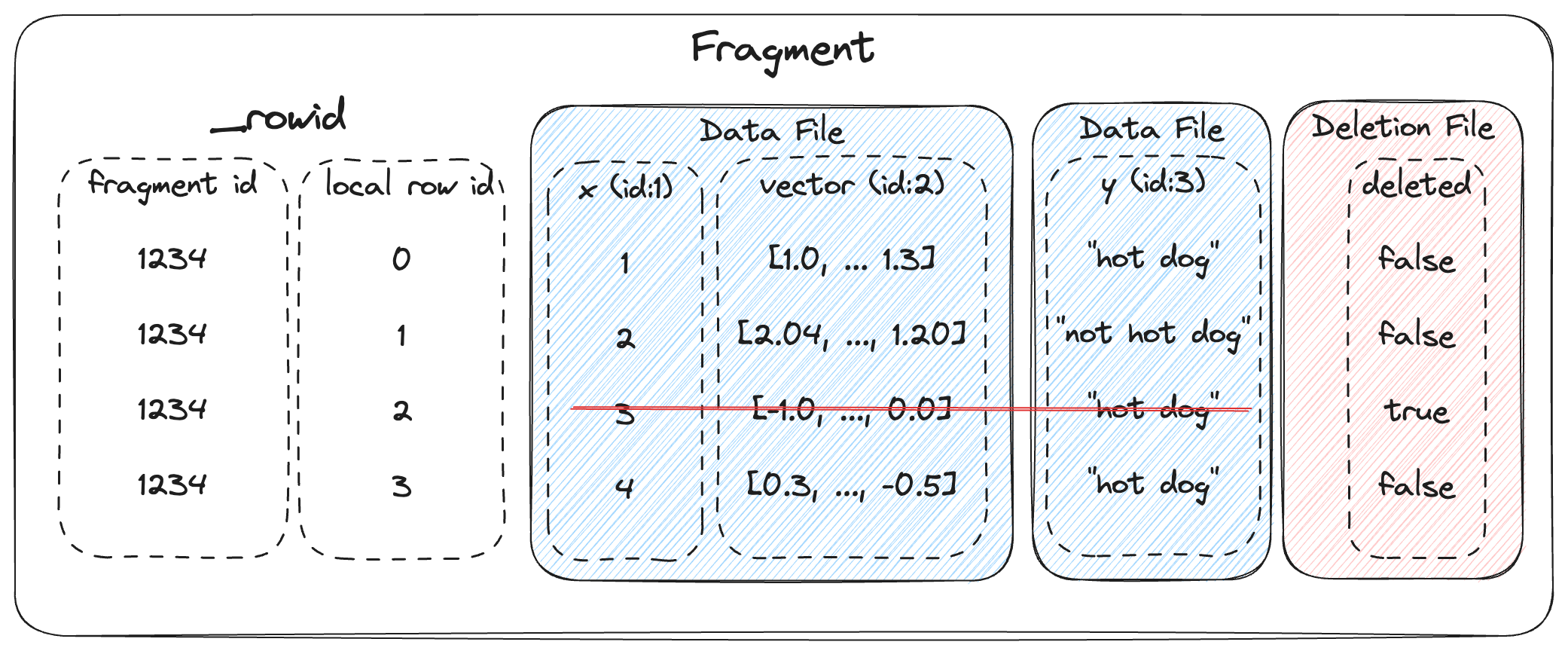
Every row has a unique id, which is an u64 that is composed of two u32s: the fragment id and the local row id. The local row id is just the index of the row in the data files.
File Structure¶
Each .lance file is the container for the actual data.
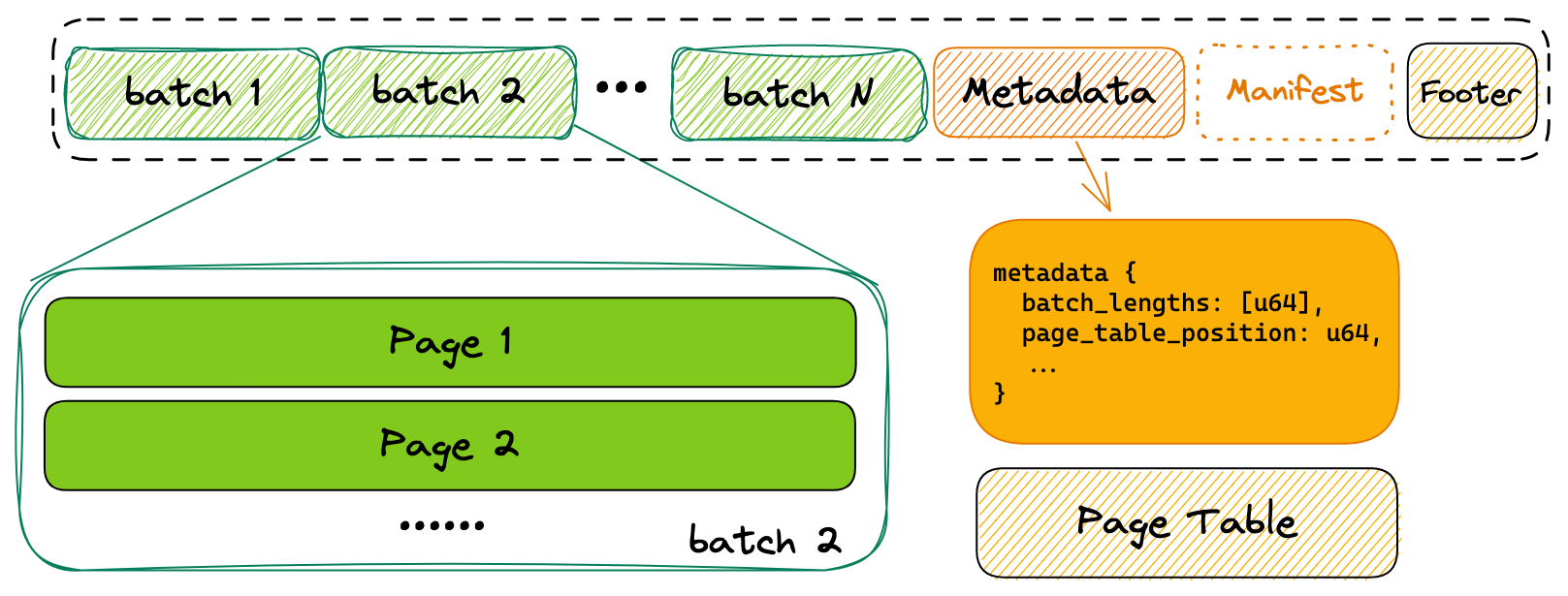
At the tail of the file, a Metadata protobuf block is used to describe the structure of the data file.
1message Metadata {
2 // Position of the manifest in the file. If it is zero, the manifest is stored
3 // externally.
4 uint64 manifest_position = 1;
5
6 // Logical offsets of each chunk group, i.e., number of the rows in each
7 // chunk.
8 repeated int32 batch_offsets = 2;
9
10 // The file position that page table is stored.
11 //
12 // A page table is a matrix of N x M x 2, where N = num_fields, and M =
13 // num_batches. Each cell in the table is a pair of <position:int64,
14 // length:int64> of the page. Both position and length are int64 values. The
15 // <position, length> of all the pages in the same column are then
16 // contiguously stored.
17 //
18 // For example, for the column 5 and batch 4, we have:
19 // ```text
20 // position = page_table[5][4][0];
21 // length = page_table[5][4][1];
22 // ```
23 uint64 page_table_position = 3;
24} // Metadata
Optionally, a Manifest block can be stored after the Metadata block, to make the lance file self-describable.
In the end of the file, a Footer is written to indicate the closure of a file:
+---------------+----------------+
| 0 - 3 byte | 4 - 7 byte |
+===============+================+
| metadata position (uint64) |
+---------------+----------------+
| major version | minor version |
+---------------+----------------+
| Magic number "LANC" |
+--------------------------------+
Feature Flags¶
As the file format and dataset evolve, new feature flags are added to the
format. There are two separate fields for checking for feature flags, depending
on whether you are trying to read or write the table. Readers should check the
reader_feature_flags to see if there are any flag it is not aware of. Writers
should check writer_feature_flags. If either sees a flag they don’t know, they
should return an “unsupported” error on any read or write operation.
Fields¶
Fields represent the metadata for a column. This includes the name, data type, id, nullability, and encoding.
Fields are listed in depth first order, and can be one of (1) parent (struct), (2) repeated (list/array), or (3) leaf (primitive). For example, the schema:
a: i32
b: struct {
c: list<i32>
d: i32
}
Would be represented as the following field list:
name |
id |
type |
parent_id |
logical_type |
|---|---|---|---|---|
|
1 |
LEAF |
0 |
|
|
2 |
PARENT |
0 |
|
|
3 |
REPEATED |
2 |
|
|
4 |
LEAF |
3 |
|
|
5 |
LEAF |
2 |
|
Encodings¶
Lance uses encodings that can render good both point query and scan performance. Generally, it requires:
It takes no more than 2 disk reads to access any data points.
It takes sub-linear computation (
O(n)) to locate one piece of data.
Plain Encoding¶
Plain encoding stores Arrow array with fixed size values, such as primitive values, in contiguous space on disk. Because the size of each value is fixed, the offset of a particular value can be computed directly.
Null: TBD
Variable-Length Binary Encoding¶
For variable-length data types, i.e., (Large)Binary / (Large)String / (Large)List in Arrow, Lance uses variable-length
encoding. Similar to Arrow in-memory layout, the on-disk layout include an offset array, and the actual data array.
The offset array contains the absolute offset of each value appears in the file.
+---------------+----------------+
| offset array | data array |
+---------------+----------------+
If offsets[i] == offsets[i + 1], we treat the i-th value as Null.
Dictionary Encoding¶
Directory encoding is a composite encoding for a Arrow Dictionary Type, where Lance encodes the key and value separately using primitive encoding types, i.e., key are usually encoded with Plain Encoding.
Dataset Update and Schema Evolution¶
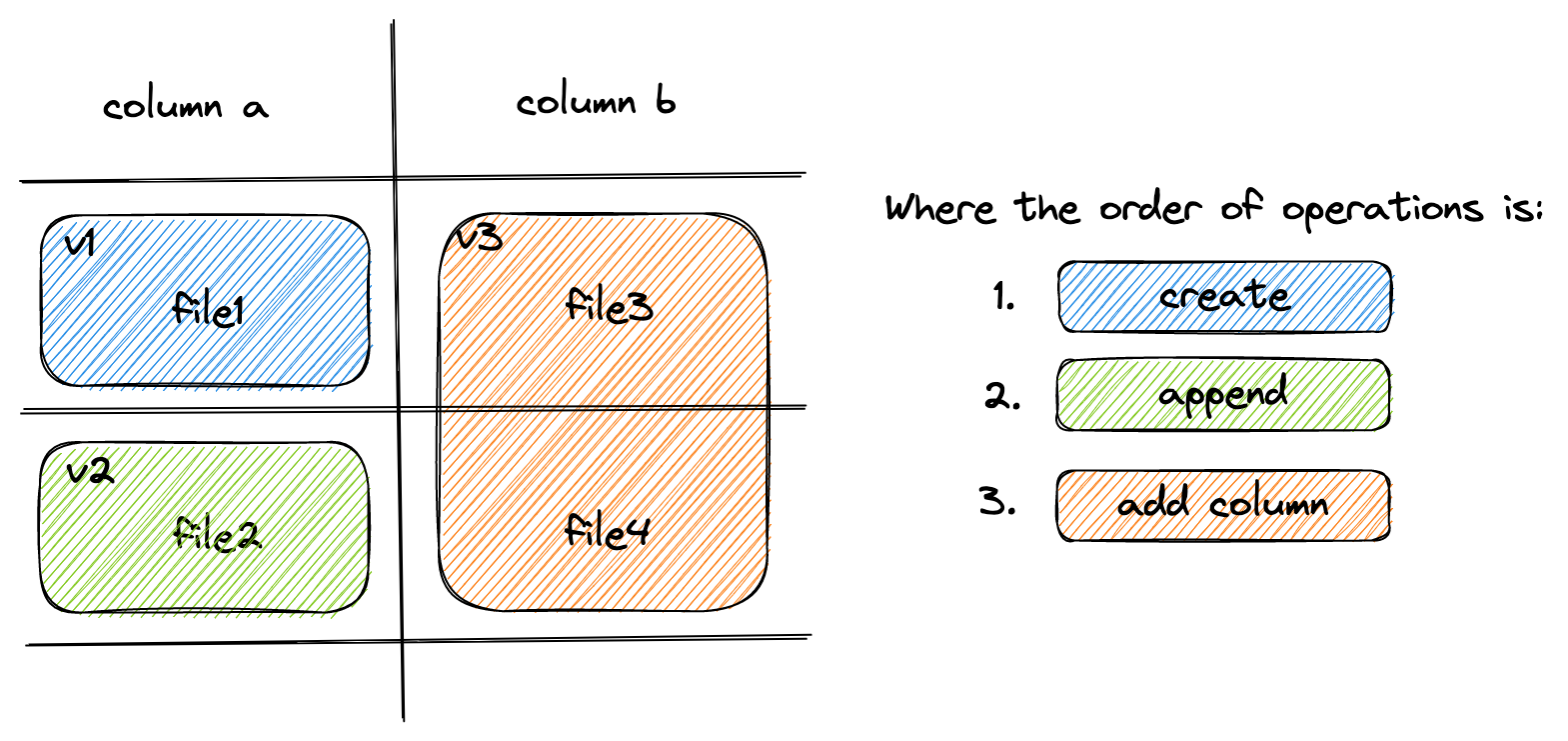
Lance supports fast dataset update and schema evolution via manipulating the Manifest metadata.
Appending is done by appending new Fragment to the dataset.
While adding columns is done by adding new DataFile of the new columns to each Fragment.
Finally, Overwrite a dataset can be done by resetting the Fragment list of the Manifest.
Deletion¶
Rows can be marked deleted by adding a deletion file next to the data in the
_deletions folder. These files contain the indices of rows that have between
deleted for some fragment. For a given version of the dataset, each fragment can
have up to one deletion file. Fragments that have no deleted rows have no deletion
file.
Readers should filter out row ids contained in these deletion files during a scan or ANN search.
Deletion files come in two flavors:
Arrow files: which store a column with a flat vector of indices
Roaring bitmaps: which store the indices as compressed bitmaps.
Roaring Bitmaps are used for larger deletion sets, while Arrow files are used for small ones. This is because Roaring Bitmaps are known to be inefficient for small sets.
The filenames of deletion files are structured like:
_deletions/{fragment_id}-{read_version}-{random_id}.{arrow|bin}
Where fragment_id is the fragment the file corresponds to, read_version is
the version of the dataset that it was created off of (usually one less than the
version it was committed to), and random_id is a random i64 used to avoid
collisions. The suffix is determined by the file type (.arrow for Arrow file,
.bin for roaring bitmap).
1// Deletion File
2//
3// The path of the deletion file is constructed as:
4// {root}/_deletions/{fragment_id}-{read_version}-{id}.{extension}
5// where {extension} is `.arrow` or `.bin` depending on the type of deletion.
6message DeletionFile {
7 // Type of deletion file, which varies depending on what is the most efficient
8 // way to store the deleted row ids. If none, then will be unspecified. If there are
9 // sparsely deleted rows, then ARROW_ARRAY is the most efficient. If there are
10 // densely deleted rows, then BIT_MAP is the most efficient.
11 enum DeletionFileType {
12 // Deletion file is a single Int32Array of deleted row ids. This is stored as
13 // an Arrow IPC file with one batch and one column. Has a .arrow extension.
14 ARROW_ARRAY = 0;
15 // Deletion file is a Roaring Bitmap of deleted row ids. Has a .bin extension.
16 BITMAP = 1;
17 }
18
19 // Type of deletion file. If it is unspecified, then the remaining fields will be missing.
20 DeletionFileType file_type = 1;
21 // The version of the dataset this deletion file was built from.
22 uint64 read_version = 2;
23 // An opaque id used to differentiate this file from others written by concurrent
24 // writers.
25 uint64 id = 3;
26} // DeletionFile
Deletes can be materialized by re-writing data files with the deleted rows removed. However, this invalidates row indices and thus the ANN indices, which can be expensive to recompute.
Committing Datasets¶
A new version of a dataset is committed by writing a new manifest file to the
_versions directory. Only after successfully committing this file should
the _latest.manifest file be updated.
To prevent concurrent writers from overwriting each other, the commit process must be atomic and consistent for all writers. If two writers try to commit using different mechanisms, they may overwrite each other’s changes. For any storage system that natively supports atomic rename-if-not-exists or put-if-not-exists, these operations should be used. This is true of local file systems and cloud object stores, with the notable except of AWS S3. For ones that lack this functionality, an external locking mechanism can be configured by the user.
Conflict resolution¶
If two writers try to commit at the same time, one will succeed and the other will fail. The failed writer should attempt to retry the commit, but only if it’s changes are compatible with the changes made by the successful writer.
The changes for a given commit are recorded as a transaction file, under the
_transactions prefix in the dataset directory. The transaction file is a
serialized Transaction protobuf message. See the transaction.proto file
for its definition.
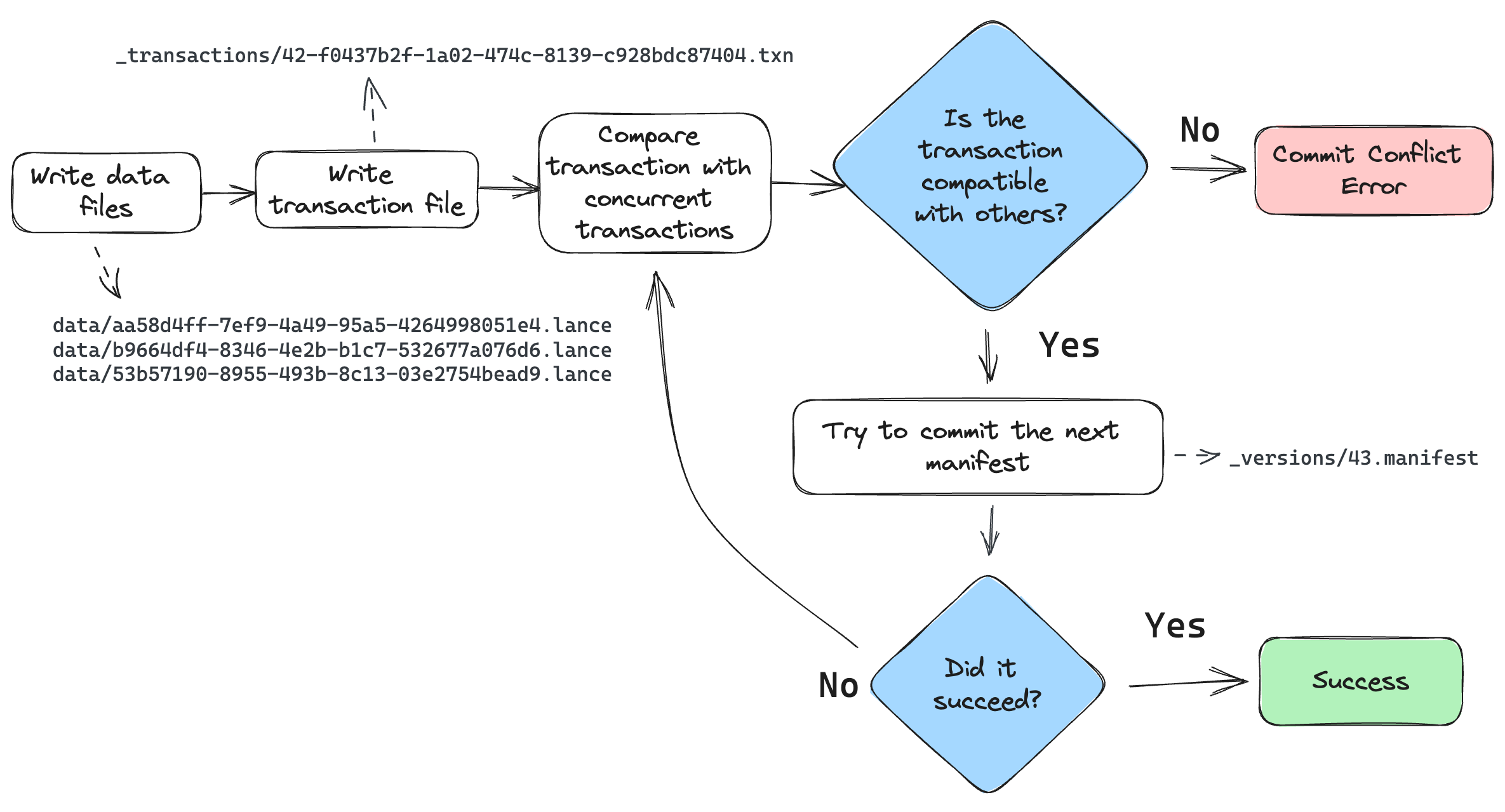
The commit process is as follows:
The writer finishes writing all data files.
The writer creates a transaction file in the
_transactionsdirectory. This files describes the operations that were performed, which is used for two purposes: (1) to detect conflicts, and (2) to re-build the manifest during retries.Look for any new commits since the writer started writing. If there are any, read their transaction files and check for conflicts. If there are any conflicts, abort the commit. Otherwise, continue.
Build a manifest and attempt to commit it to the next version. If the commit fails because another writer has already committed, go back to step 3.
If the commit succeeds, update the
_latest.manifestfile.
When checking whether two transactions conflict, be conservative. If the transaction file is missing, assume it conflicts. If the transaction file has an unknown operation, assume it conflicts.